Konsolidacja CPU
Jeszce ciekawiej przedstawia się konsolidacja zasobów procesorowych czyli CPU.
Potrzeby dyskowe o których było poprzednio mają tendencje do stałego wzrostu, natomiast zapotrzebowanie na CPU ma zupełnie inny charakter 😮.
System potrzebuje procesora w czasie przetwarzania 🙂.
Gdy skończy, to ten procesor jest bezczynny lub wykorzystany w niewielkim stopniu 🙂.
Czeka w gotowości aż aplikacja znowu będzie go potrzebował 😛.
Prosta zależność
W przypadku podejścia silosowego czyli na serwerze działa jeden system mamy trzy liczby opisujące zapotrzebowanie na CPU.
Nazwy są znaczące: MIN, MAX i AVG (średnie użycia procesora, a nie średnia z max i min 😀 ).
Spełniają one warunek:
AVG = \frac{1}{R} * \frac{MIN+MAX}{2}gdzie R – jest większe od 1, a zazwyczaj jest ok 2-4, mówi ona ile razy średnie użycie jest mniejsze od średniej z max i min.
Dla systemów o dużych pikach może być nawet 10 😳.
Oznacza to, że przez większość czasu procesor jest wykorzystywany w niewielkim stopniu.
Ale zdarzają się sytuacje, że jest go potrzeba dużo, nawet cały dostępny – tzw. piki 😮.
Brak dostępnych zasobów CPU objawia się spowolnieniem działania, ale zazwyczaj po pewnym czasie następuje „rozładowanie kolejki” i serwer pracuje normalnie 🙂.
Ponieważ nikt nie lubi czekać, dlatego trzeba mieć odpowiedni zapas 😮.
To kosztuje więc trzeba przeliczyć/porównać zniecierpliwienie w czasie oczekiwania vs. dodatkowa kasa 😳.
Założenie konsolidacji CPU
Jeżeli mamy kilka systemów to szansa, że wszystkie będą miały piki użycia CPU w tym samym czasie jest bardzo mało prawdopodobna 🙂.
Dlatego, jeśli te systemy pracują na wspólnych zasobach to każdy z nich może dostać dużo zasobów CPU, wtedy gdy potrzebuje 🙂.
Jak nie są mu potrzebne to je oddaje do puli i mogą być wykorzystywane przez inne system 🙂.
Przykład
Oczywiście założenia takie same jak poprzednio siedem systemów o rożnej wielkości.
Lecz tym razem zamiast analizować wzrost zapotrzebowania na zasoby w kolejnych latach zobaczmy jak układa się zapotrzebowanie na zasoby obliczeniowe (CPU) w 96 przedziałach czasu.
BTW liczba 96 to ilość kwadransów w dobie, taka naturalna jednostka pomiarowa w monitoringu 🙂.
Suma maksymalnego zapotrzebowania na moc obliczeniową wynosi 100 jednostek.
Załóżmy dodatkowo, że dla wszystkich siedmiu systemów minimum potrzeb CPU jest 10 razy mniejsza od MAX, a AVG jest 4 razy mniejsza od MAX 🙂.
Wówczas współczynnik z wzoru powyżej wynosi 2,2 🙂.
MAX=10 *MIN\\ AVG=2,5*MIN\\R=2,2
Otrzymujemy taki przykładowy wykres zapotrzebowania na CPU,jeżeli skonsolidujemy te siedem systemów na jednym serwerze – wspólnej mocy obliczeniowej.
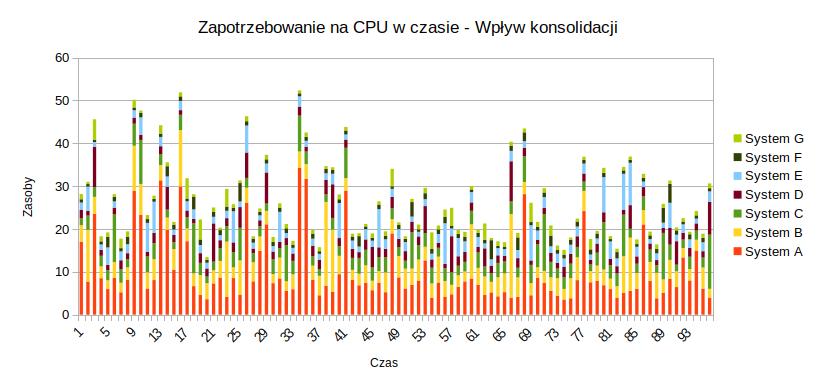
Oczywisty wniosek
Będziemy potrzebować 50% zasobów po skonsolidowaniu w stosunku do podejścia silosowego 🙂.
Ktoś powie trochę więcej – OK, jeżeli komfort pracy w tych 2% jest wart dodatkowej kasy  .
.
Tak samo jak w poprzednio udostępniam arkusz, który wykorzystałem do wygenerowania obrazka 🙂.
Proszę pamiętać, iż jest tam wykorzystana funkcja RAND() – czyli losowania liczby z przedziału 0 do 1, dlatego każda zmiana spowoduje nowe przeliczenie czyli nowe liczby, tak samo jak F9 – oblicz arkusz 🙂.
Dlatego za każdym razem będzie trochę inny obrazek 😮.
Najprostsza zmiana to zmiana liczb w komórkach C1 i D1 – te czerwone liczby 😛.
Jest tam druga zakładka, w której można przećwiczyć inne modele rozkładu.
Nie przenoszą się one od zakładki podstawowej 🙁.
Zastosowałem proste możliwości arkuszy, aby wygenerować rozkład o zadanych parametrach MIN, MAX i AVG.